|
| Perlプログラム作成のサブルーチン |
H.Kamifuji . |
- はじめに
Perlでは色々な組み込み関数を提供してくれていますが、自分で関数を定義することも可能です。ユーザーが定義する関数をサブルーチンと呼びます。サブルーチンを使うことでプログラムの中で繰り返し利用される処理を1箇所にまとめ、効率よくプログラムの記述を行うことが可能です。
ここではサブルーチンの使用方法について確認していきます。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- サブルーチンとは
[ 目次 ]
まずはサブルーチンがどのような場合に利用されるのかを確認しておきます。
下記は配列に含まれる要素を全て出力した後で、「reverse」関数を使って要素を逆順に並び替えて改めて画面に出力しています。
my @city = ("東京", "大阪", "名古屋"); print "配列の要素を出力します\n"; foreach my $var(@city){ print "$var\n"; } my @rcity = reverse(@city); print "配列の要素を出力します\n"; foreach my $var(@rcity){ print "$var\n"; }配列の中身を確認する部分で同じような処理を記述しています。今回のように2箇所であればそのまま記述しても構いませんが、プログラム中で何回も使用するような場合にはプログラムが冗長になり可読性も悪くなっていきます。
そこで同じような一連の処理を何度も行う場合には、その部分をサブルーチンとして独立し、必要に応じて呼び出すことができます。詳しいサブルーチンの使用方法は次のページ以降で解説しますけれどサブルーチンを使って先ほどのサンプルを書き直すと次のように記述できます。
my @city = ("東京", "大阪", "名古屋"); &dispArrayValue(@city); # サブルーチン呼び出し my @rcity = reverse(@city); &dispArrayValue(@rcity); # サブルーチン呼び出し # ここから下がサブルーチンです sub dispArrayValue{ my @array = @_; print "配列の要素を出力します\n"; foreach my $var(@array){ print "$var\n"; } }配列の要素を出力する部分をサブルーチン名「dispArrayValue」と言う名前でサブルーチンとして記述し、必要に応じて呼び出しています。最初のサンプルよりもむしろ長くなった気がしますが、さらに配列の中身を確認する必要ができた場合でもサブルーチンを呼び出す1行だけを追加するだけで済みます。
my @city = ("東京", "大阪", "名古屋"); &dispArrayValue(@city); my @rcity = reverse(@city); &dispArrayValue(@rcity); my @rrcity = reverse(@rcity); &dispArrayValue(@rrcity); sub dispArrayValue{ my @array = @_; print "配列の要素を出力します\n"; foreach my $var(@array){ print "$var\n"; } }このようにサブルーチンは同じような一覧の処理をまとめるために使用します。詳しくは次のページ以降で解説していきます。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# サブルーチンとは # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @city = ("東京", "大阪", "名古屋"); &dispArrayValue(@city); my @rcity = reverse(@city); &dispArrayValue(@rcity); sub dispArrayValue{ my @array = @_; print "配列の要素を出力します\n"; foreach my $var(@array){ print "$var\n"; } }上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
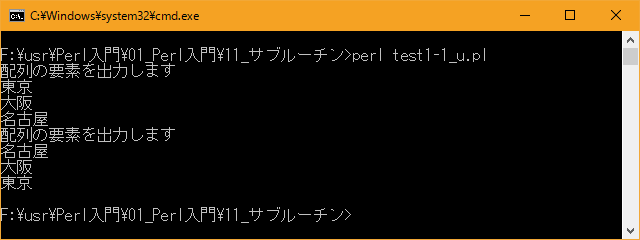
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test1-1_u.pl | nkf -w 配列の要素を出力します 東京 大阪 名古屋 配列の要素を出力します 名古屋 大阪 東京 [xxxxxxxx@dddddddddd Sub]$
- サブルーチンの定義
[ 目次 ]
ではサブルーチンの定義方法から確認していきます。書式は次の通りです。
sub サブルーチン名{ 実行する処理; }サブルーチンは「sub」の後に空白を1文字空けてからサブルーチン名を記述します。そしてサブルーチンで実行する処理を「{」から「}」で囲まれたブロック中に記述して行きます。実行される処理は複数記述することが出来ます。
サブルーチン名として記述する名前は変数と同じくアルファベット・数字・アンダーバー("_")が使用できます。ただし先頭に数字は使用できません。
サブルーチン内には実行する処理を記述していきます。必須ではありませんが、各行の先頭はインデント(字下げ)してどこからどこまでがブロック内の処理なのか視覚的に分かるように記述します。
サブルーチンの定義位置
サブルーチンはプログラム中のどこで定義しても構いません。一般的にはプログラム内の先頭や最後にまとめて定義します。
print "サブルーチンのテスト\n"; sub hello{ print "hello\n"; } sub bye{ print "bye\n"; }上記の場合は2個のサブルーチンをプログラム内の最後に続けて定義しています。このようにサブルーチンはプログラム中に複数定義することが可能です。
サブルーチンはいつ実行されるか
Perlのプログラムは処理を記述した順に上から下へ順に実行されていきますが、サブルーチン内に記述された処理はプログラム内からサブルーチンを呼び出さない限り実行されません。
例えば次のようなプログラムで考えてみます。
sub hello{ print "hello\n"; } print "サブルーチンのテスト\n"; sub bye{ print "bye\n"; } print "終了\n";このプログラムではまずサブルーチンが定義されていますが、サブルーチンのブロック内で記述された処理は実行されません。その為、「print "サブルーチンのテスト\n";」がまず実行され、その次に「print "終了\n";」が実行されてプログラムは終了します。
このようにサブルーチン内の処理はサブルーチンが呼び出されない限り実行されません。(ただし先ほど記述した通り、サブルーチンは最初か最後にまとめておいた方が分かりやすいプログラムになります)。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# サブルーチンの定義 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; sub hello{ print "hello\n"; } print "サブルーチンのテスト\n"; sub bye{ print "bye\n"; } print "終了\n";上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test2-1_u.pl | nkf -w サブルーチンのテスト 終了 [xxxxxxxx@dddddddddd Sub]$
- サブルーチンの呼び出し
[ 目次 ]
サブルーチンを定義したらプログラムの中から呼び出して使用します。サブルーチンを呼び出す時の書式は次の通りです。
&サブルーチン名; sub サブルーチン名{ 実行する処理; }サブルーチンの呼び出しはアンパサンド(&)の後に呼び出すサブルーチン名を記述します。
サブルーチンの呼び出しが行われると、処理の順序はサブルーチン内へ移動します。
次の例で考えてみます。
print "サブルーチンのテスト\n"; &hello; print "終了\n"; sub hello{ print "hello\n"; }上記の場合は「&hello;」の処理が実行されサブルーチン内へ処理が移ります。よって「print "hello\n";」が実行されます。そして呼び出されたサブルーチンのブロック内の処理が全て終了すると、サブルーチンを呼び出した処理の次の処理が実行されます。すなわち「print "終了\n";」が実行されます。
よって上記のサンプルを実行すると次のような出力結果となります。
サブルーチンのテスト hello 終了
このようにサブルーチンはプログラム中のどこに記述されていたとしても、サブルーチンが呼び出された時点でサブルーチンのブロック内の処理が実行されます。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# サブルーチンの呼び出し # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; sub hello{ print "hello\n"; } print "サブルーチンのテスト\n"; &hello; &bye; print "終了\n"; sub bye{ print "bye\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
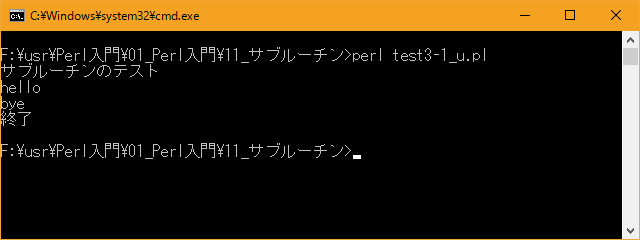
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test3-1_u.pl | nkf -w サブルーチンのテスト hello bye 終了 [xxxxxxxx@dddddddddd Sub]$
- 引数
[ 目次 ]
サブルーチンを利用することで、同じような処理を1箇所にまとめることが出来ます。ここではさらに進んでサブルーチンに引数を渡す方法を確認します。
例えば次の例で考えてみます。
my $ave; $ave = (10 + 8) / 2; print "10 と 8 の平均値は $ave です\n"; $ave = (5 + 17) / 2; print "5 と 17 の平均値は $ave です\n";
2つ数字の平均値を計算して表示しています。このサンプルの平均の計算と画面の出力部分をサブルーチンにしてみます。サブルーチンは共通して使用されるものですのでサブルーチンの中に数字を直接記述することはできません。その為、サブルーチン内では変数を使って計算式を記述しておき、サブルーチンが呼び出される度に変数に数値を格納します。
ここで使用されるのが引数です。引数とはサブルーチンを呼び出す時に、複数の値を渡す時に使用します。引数付きでサブルーチンを呼び出すには次の書式を使います。
&サブルーチン名(引数1, 引数2, ...); sub サブルーチン名{ 実行する処理; }引数は1つだけではなく複数の値を指定することが出来ます。引数を付けてサブルーチンを呼び出す時は、サブルーチン名の後に括弧()を付け、括弧の中に引数を記述します。複数の引数を記述したい場合はカンマ(,)で区切って続けて記述して下さい。
次にサブルーチン側では渡されてきた値が自動的に配列変数「$_」に格納されます。よってサブルーチン内で渡されてきた引数を使用したい場合には、1番目の引数は「$_[0]」で参照できますし、2番目の引数は「$_[1]」で参照できます。
サブルーチンに渡されてきた引数が格納される配列変数 $_ 1番目の引数を参照する場合は $_[0] 2番目の引数を参照する場合は $_[1] ... n番目の引数を参照する場合は $_[n-1]
では先ほどのサンプルをサブルーチンを使って書き換えてみます。サブルーチンを呼び出す時に、平均を計算したい2つの値を引数としてサブルーチンに渡し、サブルーチン側では渡されてきた引数の値を取り出して平均を計算し表示します。
&calcAverage(10, 8); &calcAverage(5, 17); sub calcAverage{ my $ave; $ave = ($_[0] + $_[1]) / 2; print "$_[0] と $_[1] の平均値は $ave です\n"; }今回はサブルーチン「calcAverage」を定義し、2つの引数の平均を計算して画面に出力するようにしています。サブルーチンを呼び出す側では平均を計算したい2つの値を引数に指定しています。
このように引数を使用すると、単純に同じことをするだけのサブルーチンだけではなくより複雑なことが出来るサブルーチンを定義することが出来ます。
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 引数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; &calcAverage(10, 8); &calcAverage(5, 17); sub calcAverage{ my $ave; $ave = ($_[0] + $_[1]) / 2; print "$_[0] と $_[1] の平均値は $ave です\n"; }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test4-1_u.pl | nkf -w 10 と 8 の平均値は 9 です 5 と 17 の平均値は 11 です [xxxxxxxx@dddddddddd Sub]$
- 引数を任意の変数に格納
[ 目次 ]
サブルーチン側では、呼び出し元から渡されてきた引数をデフォルトの配列変数「$_」に格納します。このまま使用しても問題はありませんが、サブルーチン内で使用する時にどのような値が格納されたものなのか分かりにくい変数名となっているため間違いをしやすく可読性も悪くなっています。
そこでサブルーチンでは渡されてきた引数を任意の引数に一度格納する処理がよく行われます。では実際の例で考えてみましょう。
&personal("加藤", 25, "東京都"); sub personal{ print "名前は $_[0] です\n"; print "年齢は $_[1] です\n"; print "住所は $_[2] です\n"; }引数は3つ使用されていますのでサブルーチン内では$_[0]から$_[2]で参照しています。これくらいのプログラムなら問題はありませんが、複雑な処理をサブルーチン内で記述する場合には$_[0]や$_[2]ではどんな値が格納されているか分かりにくいため間違えやすくなります。そこでサブルーチンの冒頭で渡されてきた引数を適切な変数に一度格納します。
nal("加藤", 25, "東京都"); sub personal{ my ($name, $old, $address) = @_; print "名前は $name です\n"; print "年齢は $old です\n"; print "住所は $address です\n"; }ここでは特に特別なことをしているわけではありません。配列変数に格納された値を別途用意した変数に格納しているだけです。ただ適切な変数名を持つ変数を使用することで間違えにくく分かりやすいプログラムを記述できます。
引数が1つの場合の注意点
引数が1つだけだった場合には注意が必要です。例えば次のように記述してしまうと予期せぬ結果となります。
sub personal{ my $name = @_; }変数「$name」に対して配列である「@_」を格納しています。配列を単独の変数に格納した場合、配列の要素数が変数に格納されてことになっていますので、この場合は引数の値が何であっても変数「$name」には引数の数である「1」が格納されます。
引数が1つの場合の正しい記述方法は次の通りです。
sub personal{ my $name; ($name) = @_; }この場合は、要素が1つのリストに対して配列を格納しています。よって変数「$name」には配列の1番目の要素である「$_[0]」の値が格納されます。もちろん下記のように宣言と同時に格納しても構いません。
sub personal{ my ($name) = @_; }では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 引数を任意の変数に格納 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; &personal("加藤", 25, "東京都"); sub personal{ my ($name, $old, $address) = @_; print "名前は $name です\n"; print "年齢は $old です\n"; print "住所は $address です\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
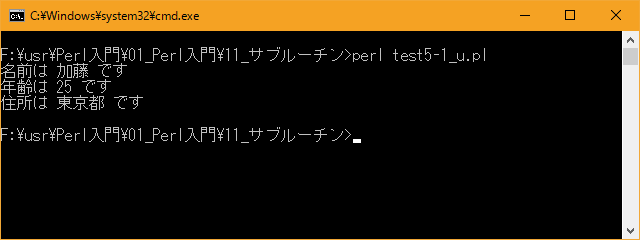
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test5-1_u.pl | nkf -w 名前は 加藤 です 年齢は 25 です 住所は 東京都 です [xxxxxxxx@dddddddddd Sub]$
- 戻り値
[ 目次 ]
サブルーチンでは呼び出し元に何らかの値を返すことが出来ます。例えばサブルーチン内で計算を行い、その結果である数値を呼び出し元に返すということが可能です。サブルーチンから呼び出し元に返す値を「戻り値」と呼びます。
サブルーチンで戻り値を使用するのに特別な処理は必要ありません。全てのサブルーチンは必ず戻り値を返す処理を行います。今まではそれを呼び出し元で利用していませんでした。
サブルーチンからの戻り値を呼び出し元で使用するには次のように記述します。
変数 = &サブルーチン名;
サブルーチンの呼び出しが行われるた結果、戻り値を変数に格納しています。具体的には次のように記述します。
my $sum; $sum = &calcTwoNum(10, 23); print "$sum"; sub calcTwoNum{ my ($num1, $num2) = @_; $num1 + $num2; }この場合では変数「$sum」にサブルーチンからの戻り値が格納されます。
戻り値の指定方法
次にサブルーチンではどのような値を戻り値として返すのかを確認します。サブルーチンでは最後に評価された結果を戻り値として返すことになっています。
例えば先ほどのサンプルを見てください。
sub calcTwoNum{ my ($num1, $num2) = @_; $num1 + $num2; }サブルーチンの最後で変数「$num1」と変数「$num2」を加算しています。加算した結果を他の変数に格納したり出力せずにただ加算だけしています。エラーではありませんが単に計算だけをしているのでサブルーチンの中では意味を持ちませんが、サブルーチンでは最後に行われた計算の結果が戻り値として設定されるためこの加算の結果がサブルーチンの戻り値となります。
このように最後に計算が行われた場合は計算の結果が戻り値となります。単に数値や戻り値などの値が記述してあった場合はその値が戻り値となります。それ以外の処理の場合、処理に応じて評価された結果が戻り値となります。
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 戻り値 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my ($sum, $str); $sum = &calcTwoNum(10, 23); print "$sum\n"; $sum = &calcTwoNum(32, 14); print "$sum\n"; sub calcTwoNum{ my ($num1, $num2) = @_; $num1 + $num2; }上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。
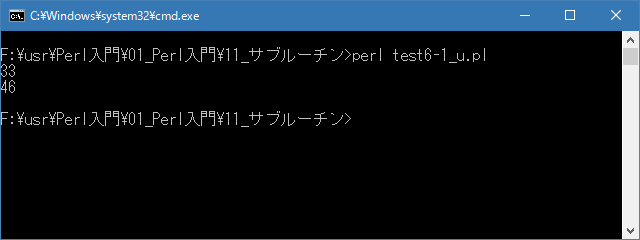
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test6-1_u.pl | nkf -w 33 46 [xxxxxxxx@dddddddddd Sub]$
- return文
[ 目次 ]
サブルーチンではブロックの最後まで処理が進むと呼び出し元に返りますが、任意の位置で即座に呼び出し元に処理を返すことが出来ます。「return」文を使います。
return;
「return」文が実行されると呼び出し元に処理が戻ります。「return」文でサブルーチンが終了した場合には、戻り値として空の値が設定されます。空の値とは呼び出し元が値を求めている場合は未定義値「undef」となりリストを求めている場合は空のリストとなります。
また「return」文が実行される時に戻り値を指定することも可能です。この場合の書式は次のようになります。
return 戻り値;
この場合、呼び出し元に処理が戻ると共に戻り値が指定した値に設定されます。
例えば次のように使用します。
my $msg; $msg = &hantei(72, 84); print "$msg"; sub hantei{ my ($kokugo, $suugaku) = @_; if ($kokugo < 75){ return "不合格"; } if ($suugaku < 75){ return "不合格"; } "合格"; }今回の場合は呼び出し元から2つの教科の成績が引数として渡されてきます。成績を順に判定し、不合格の場合は「return」文を使いその時点でサブルーチンを終了し呼び出し元に値を返します。2つの教科の判定が問題無かった場合は最後に戻り値を設定してサブルーチンが終了します。
return文の使い方
return文はサブルーチンの途中で呼び出し元に処理を戻す場合に使用されるものですが、戻り値を明確に記述することが出来るためサブルーチンの最後でも意識的に使用する場合もあります。
例えば先ほどのサンプルの最後の部分を書き換えてみます。
my $msg; $msg = &hantei(72, 84); print "$msg"; sub hantei{ my ($kokugo, $suugaku) = @_; if ($kokugo < 75){ return "不合格"; } if ($suugaku < 75){ return "不合格"; } return "合格"; }サブルーチンの最後の「return」は記述する必要はありませんが、戻り値が何であるかを明確に出来ます。これはどちらでも構いませんが個人的には「return」を付けるのが好みです。出来る限り必要無い記述は省略するという考え方もあるようです。
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# return文 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $msg; $msg = &hantei(72, 84); print "$msg\n"; $msg = &hantei(92, 80); print "$msg\n"; sub hantei{ my ($kokugo, $suugaku) = @_; if ($kokugo < 75){ return "不合格"; } if ($suugaku < 75){ return "不合格"; } return "合格"; }上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。
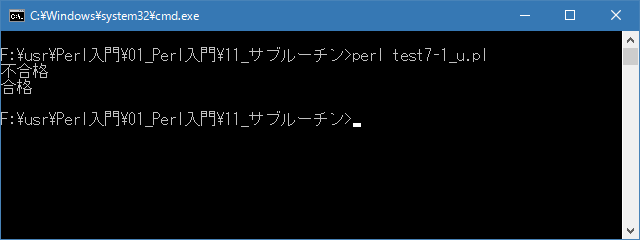
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Sub]$ perl test7-1_u.pl | nkf -w 不合格 合格 [xxxxxxxx@dddddddddd Sub]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/03 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]