|
| Perlプログラム作成のハッシュ |
H.Kamifuji . |
- はじめに
リストや配列と同じくハッシュも複数の値を管理するために使用されます。大きく異なる点はハッシュではインデックスの代わりに名前を使ってハッシュに含まれる要素を管理できる点です。ここではハッシュの使い方について確認していきます。
※ハッシュに関する関数は「ハッシュ」を参照して下さい。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- ハッシュとは
[ 目次 ]
複数の値を管理するものとして配列については既に解説しました。配列に格納される要素は順序を持って格納されており、インデックスと呼ばれる数値で管理していました。
複数の値をまとめて管理するためにインデックスを使うのは大変簡潔で便利です。ただ、例えば名前に関連付けて住所や電話番号を管理したい場合には少し面倒です。配列でこのようなことを行うとすれば、まず名前を管理する配列を用意し、ある名前を格納します。そして住所の配列を別途用意し、対応する名前に割り当てられているインデックスを調べ、住所の配列に同じインデックスで名前に対応した住所を格納します。
my @name; my @address; $name[0] = "katou"; $address[0] = "Tokyo";
ただ、このような場合にはハッシュを使うと大変便利です。ハッシュは他のプログラミング言語では連想配列とも呼ばれているもので、複数の値を管理することは配列と同じですが、要素を順に並べてインデックスで管理するのではなく、格納される値に対するキーを別途設定しインデックスの代わりにキーで管理します。
キーには任意の文字列を指定できます。その為、例えばキーに名前を指定しておけば、その名前に対応した値を取り出すことが行えます。例えば先ほどの例をハッシュを使って記述すると次のようになります。
my %address; $address{'katou'} = "Tokyo";配列ではインデックスを指定していた箇所にキーとなる文字列が指定されています。このようにハッシュではキーと値をペアとして格納していきます。ハッシュから値を取り出す時も同じです。
my %address; $address{'katou'}= "Tokyo"; print "$address{'katou'} \n";配列の場合と比べて「katou」と言う名前に対する住所を取り出すのが直接的で分かりやすくなっています。ハッシュを使うことで、極めて簡単なデータベースのように何かに対応する値を取り出すといったことが用意となります。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ハッシュとは # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address; $address{'katou'}= "Tokyo"; $address{'山田'}= "大阪"; print "$address{'katou'} \n"; print "$address{'山田'} \n";上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
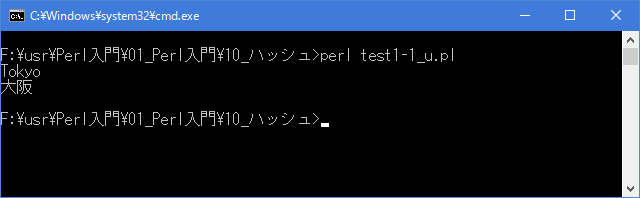
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test1-1_u.pl | nkf -w Tokyo 大阪 [xxxxxxxx@dddddddddd Hash]$
- ハッシュの宣言と要素へのアクセス
[ 目次 ]
変数や配列の場合と同じくハッシュを使用する場合も宣言を行います。変数の場合はプレフィックス名して「$」を使用し配列の場合は「@」を使用しますがハッシュの場合は「%」を使用します。
%ハッシュ名
例えばハッシュ名として「name」を使ったハッシュを宣言する場合は次のようになります。
my %name;
ハッシュは配列と同じく複数の値を管理しており、1つ1つは要素と呼ばれ要素はそれぞれ変数です。要素に対する扱いは配列と同じく1つの値を管理できる変数をまとめて管理することにより複数の値を管理できるようになっています。
1つのハッシュで管理できる要素数も制限はありません。また宣言時に要素数を指定する必要もありません。
ハッシュへの値の格納と取得
ハッシュではキーと値をペアで登録します。配列の場合と異なりハッシュでは格納された値に順序はありません。複数の値が格納されている時にどんな並びで格納されているかは決まっていません。その代わり値に対するキーを同時に登録し、格納された値はキーを指定することにより取り出します。
その為、1つのハッシュでは同じキーを重複して使用し別の値を登録することは出来ません(値は重複していても構いません)。
具体的にハッシュに値を格納するには次のように行います。
$ハッシュ名{キー} = 値;ハッシュに含まれる要素は1つ1つが変数ですので、キーを指定して値を格納する場合は、プレフィックスが「%」ではなくて「$」となりますので注意して下さい。配列の場合はインデックスを[]で囲いましたがハッシュの場合はキーを{}で囲います。
キーには任意の文字列を指定します。文字列そのものだけではなく、文字列が格納された変数なども指定できます。
my %name; $name{'山田'}= "太郎"; my $str = "鈴木"; $name{$str}= "一郎";配列の場合と異なり順序がありませんので、新しいキーに対して値を設定すると要素が自動的に追加されます。既にあるキーに対して値を設定すれば格納されていた値が上書きされます。
要素に格納された値を取得する場合も変数や配列の場合と基本的に代わりありません。ハッシュの要素の場合は「$ハッシュ名{キー}」で参照できます。
my %name; $name{"鈴木"}= "一郎"; $name{'山田'}= "太郎"; print "$name{'山田'}\n";では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ハッシュの宣言と要素へのアクセス # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %names; $names{"鈴木"}= "一郎"; $names{'山田'}= "太郎"; my $name = "山田"; print "$names{$name}\n";上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
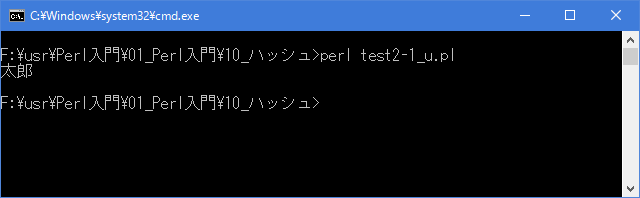
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test2-1_u.pl | nkf -w 太郎 [xxxxxxxx@dddddddddd Hash]$
- ハッシュの初期化
[ 目次 ]
ハッシュについても宣言と同時に初期化することが可能です。初期化するにはリストを使って次のように記述します。
my @ハッシュ名 = (キー1,値1,キー2,値2,...,キーn,値n);
ハッシュはキーと値をペアとして使用しますのでリストを指定する場合にはキーと値を交互に指定して下さい。例えば次のように記述します。
my @old = ("加藤", 28, "山下", 19);これは次のように記述した場合とほぼ同じです。
my @old; $old{"加藤"} = 28; $old{"山下"} = 19;1つのハッシュで管理できる要素数も制限はありません。また宣言時に要素数を指定する必要もありません。
初期化を行う場合の別の形式
ハッシュの初期化にリストを指定する場合、キーと値を交互に並べていきますのでリストが長くなった時にリスト内に記述された値のどちらがキーでどちらが値か分かりにくい時があります。
そこでハッシュに対して初期化を行う場合には次のような記述方法も用意されています。
my @ハッシュ名 = (キー1=>値1, キー2=>値2,..., キーn=>値n);
Perlではリストの中でコンマ(,)と=>は同じ扱いとなります。その為、記述方法は異なりますがリストとしての意味はまったく変わっていません。ただ人間の目から見たときにリスト内に書かれた値のどちらがキーでどちらが値なのかは分かりやすくなります。
その為、ハッシュに対して初期化をする場合には上記の記述方法がよく使用されるようです。リストが長くなるような場合などはより分かりやすくなるように次のような記述もよく行われます。
my @ハッシュ名 = ( キー1 => 値1, キー2 => 値2, ... , キーn => 値n );
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ハッシュの初期化 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); print "$address{'鈴木'}\n"; print "$address{'山田'}\n";上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
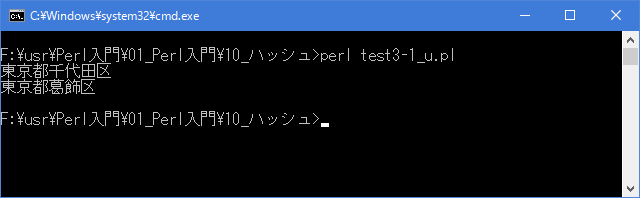
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test3-1_u.pl | nkf -w 東京都千代田区 東京都葛飾区 [xxxxxxxx@dddddddddd Hash]$
- 文字列中に含まれるハッシュの変数展開
[ 目次 ]
ダブルクォーテーションで囲まれた文字列中に配列が含まれていると、配列の要素がスペースで区切られて展開されました。ではハッシュの場合はどうかと言うとハッシュ全体を表す「%ハッシュ名」のような記述を行っても展開はされません。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); print "%address\n";
上記の場合は単に「%address」と言う文字列が出力されます。
このようにハッシュ全体を文字列の中で変数展開する手段は用意されていません。ただ、ハッシュの要素1つ1つは変数ですので、ハッシュの要素をダブルクォーテーションで囲まれた文字列の中に記述した場合は他の変数と同じく変数展開されます。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); print "$address{'鈴木'}\n";上記の場合は「東京都千代田区」と言う文字列が出力されます。
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ハッシュ要素の変数展開 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); print "%address\n"; print "$address{'鈴木'}\n";上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
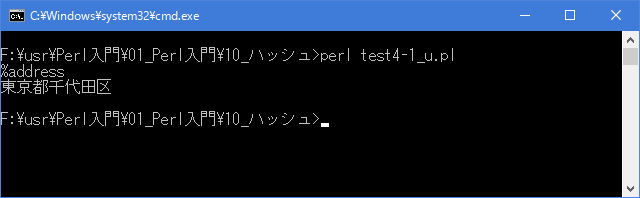
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test4-1_u.pl | nkf -w %address 東京都千代田区 [xxxxxxxx@dddddddddd Hash]$
- ハッシュと繰り返し処理
[ 目次 ]
配列と同じくハッシュに含まれる要素を順に取り出して処理するといったことはよく行われる処理です。
配列と異なりインデックスで管理されていないため、主にforeach文またはwhile文を使います。まずfor文から試してみます。
foreach文の場合にはハッシュに含まれるキーのリストを作成し順に取り出して処理することになります。次のように記述できます。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); foreach my $key(keys(%address)){ print "$address{$key}\n"; }「keys」関数は対象となるハッシュに含まれている全てのキーをリストの形で返します。詳しくは「keys関数」を参照して下さい。
キーと値をペアで順に取り出す場合にはwhile文を使います。次のように記述できます。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); while (my ($key, $value) = each(%address)){ print "key=$key, value=$value\n"; }「each」関数は対象となるハッシュに含まれている要素を順に取り出します。詳しくは「each関数」を参照して下さい。
ハッシュの要素には順序がありませんので、どちらの場合も要素がどのような順序で取り出されるかは分かりません。
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ハッシュと繰り返し処理 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); foreach my $key(keys(%address)){ print "$address{$key}\n"; } while (my ($key, $value) = each(%address)){ print "key=$key, value=$value\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test5-1_u.pl | nkf -w 東京都葛飾区 東京都千代田区 key=山田, value=東京都葛飾区 key=鈴木, value=東京都千代田区 [xxxxxxxx@dddddddddd Hash]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/03 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]